Celery ETA Tasks Demystified
| published by | Oleg Pesok |
|---|---|
| in blog | Instawork Engineering |
| original entry | Celery ETA Tasks Demystified |

At Instawork, we use Celery to queue and process background tasks from our Django code. Typically, we want the tasks to be processed as quickly as possible. But sometimes we want a task to be processed at a specific point in the future. For example, we may want to send a reminder notification to our users 1 hour before the start of their shift. Celery offers a convenient way to do this by providing an eta or countdown value when queueing the task from Django. This seems like a perfect solution for us, but in practice we encountered many problems with using countdown or eta. Celery’s documentation was lacking in describing how these features are implemented, so we did a deep dive into Celery’s internals to understand the feature. Based on our findings (described in this post), countdown and eta should be used rarely; there are more reliable ways to process tasks at specific points in the future.
Celery Queueing
Let’s begin by talking briefly about how the Celery queues work. In our environment, we use Redis as our backing store for our queues. This means that each queue (default and any others explicitly defined) get a top level key in Redis and each key contains a list of tasks. When the queue is empty, the key does not exist, this is why manually inspecting all keys will not always show all of the available queues. In fact, most of the time you won’t see the key if you inspect Redis because queues are often empty!
Now, how does a Celery task go from getting queued to execution? The process is relatively straightforward.
- When task.delay() is called on a properly annotated task, an entry is added to the queue’s key in Redis.
- Celery workers poll the queues and pulls available tasks. When a worker pulls a task, it removes it from the named queue and moves it to a special Redis unacked queue.
- The worker holds on to the task in memory, until it can process it.
- Once the worker successfully processes the task, it removes the task from unacked Redis queue.
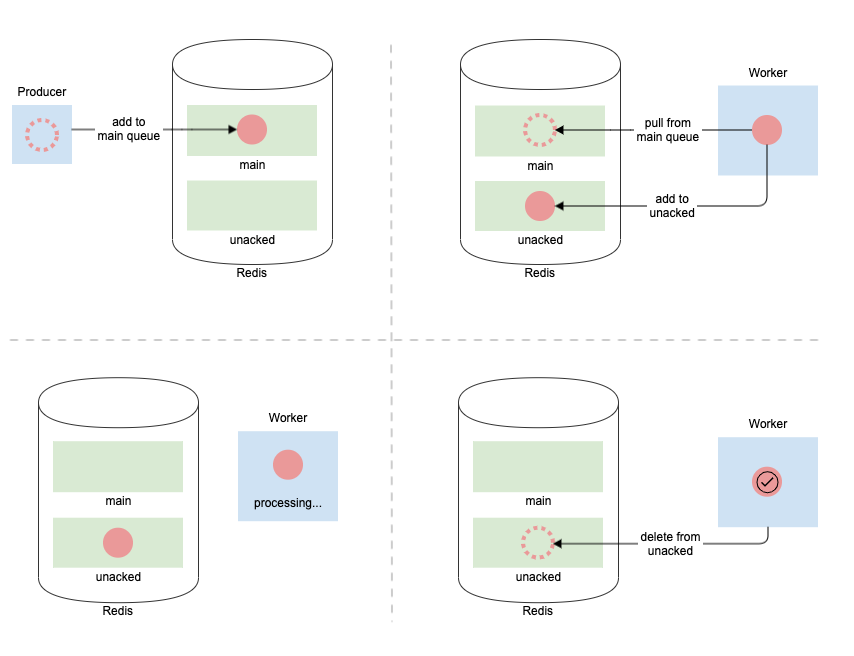
What’s the purpose of the unacked queue? For efficiency, workers actually prefetch more tasks than they can immediately handle. But workers can get killed/shut down before processing all prefetched tasks. When this happens, we don’t want to lose the prefetched tasks. The unacked queue allows other workers to process tasks in these circumstances.
Unacked deep-dive
How exactly does the unacked queue work? Firstly, it’s not actually a queue. It’s a hash map between a uuid which is NOT the Celery assigned task_id and the task message itself. There is a secondary queue that is actually used to pull items from this map. This queue is called unacked_index and it’s implemented as a sorted set. This queue stores the same uuid and is sorted by a timestamp. The timestamp indicates when the item was added to the unacked queue.
There’s a third component to the entire unacked system, and that’s the unacked_mutex. This is a single string that is created whenever a worker wants to pull things from unacked. The string has a time-to-live (TTL) that effectively means that this is an expiring lock. Hopefully a worker can finish processing before the lock expires! It also prevents a deadlock condition where a worker dies mid-way through processing unacked and there are other workers waiting to do the same. We’ve observed that somehow this unacked_mutex can get stuck in a state where it does not have a TTL. This led to unacked never being re-scanned/processed. Possibly this was through a manual accident or something about the implementation changed during an upgrade, etc.
Visibility Timeout
Now that we understand roughly how unacked works, the next question is how often this “queue” gets scanned. This is controlled by the visibility_timeout setting. This timeout determines how old a task has to be before we consider it “orphaned” and re-queue it elsewhere. It is very important to understand how the visibility timeout works with Celery & Redis. It must be carefully tuned based on your application’s needs. We will cover it in some detail here, but read the docs for full information. Let’s work through some examples.
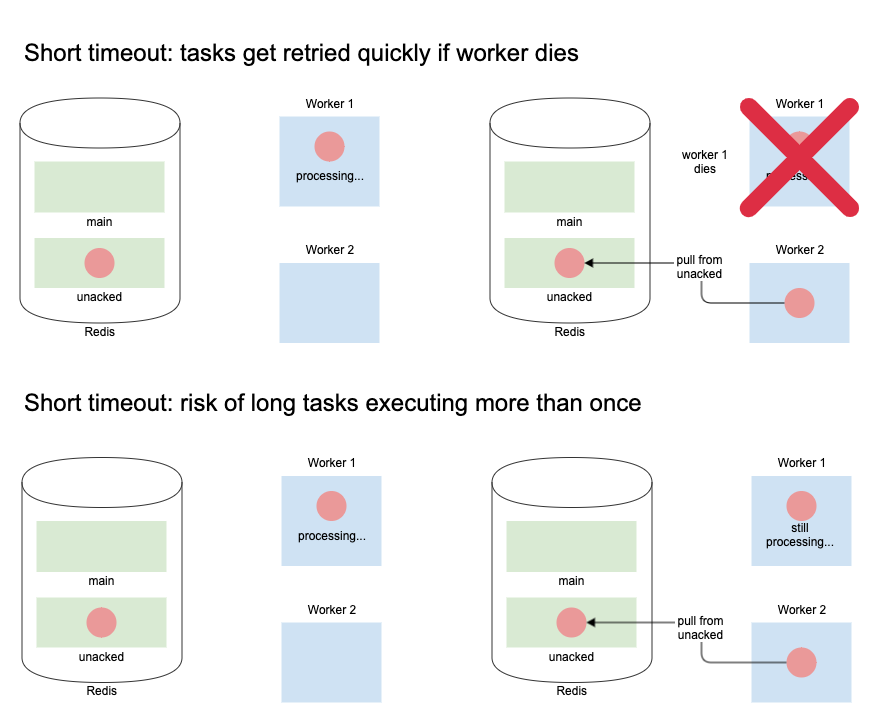
Short Visibility Timeout (30 seconds)
Let’s say the visibility timeout is really short, 30 seconds for example. This means that when a worker picks up this task, it gets put on the unacked queue, and the worker hangs on to it until it's ready to execute.
If the worker dies before executing the task, a different worker will come in after 30 seconds, look at the unacked queue, and pull the same task. This is good, because we only experience a minor delay in processing the task.
What if the worker is stuck processing other tasks all running for 5 minutes? Same thing: a different worker comes in after 30 seconds, looks at the unacked queue, and pull the same task. Now we have the same task pulled by two different workers! If the second worker is also backed up, it’s possible a third worker will pull the same task from the unacked queue. We now have 3 workers all hanging on to the same task. The first one to start will ack the task and remove it from the unacked queue preventing it from processing any more times. But the 3 task executions may cause a bad experience in the application (say, if send a user the same email 3 times).
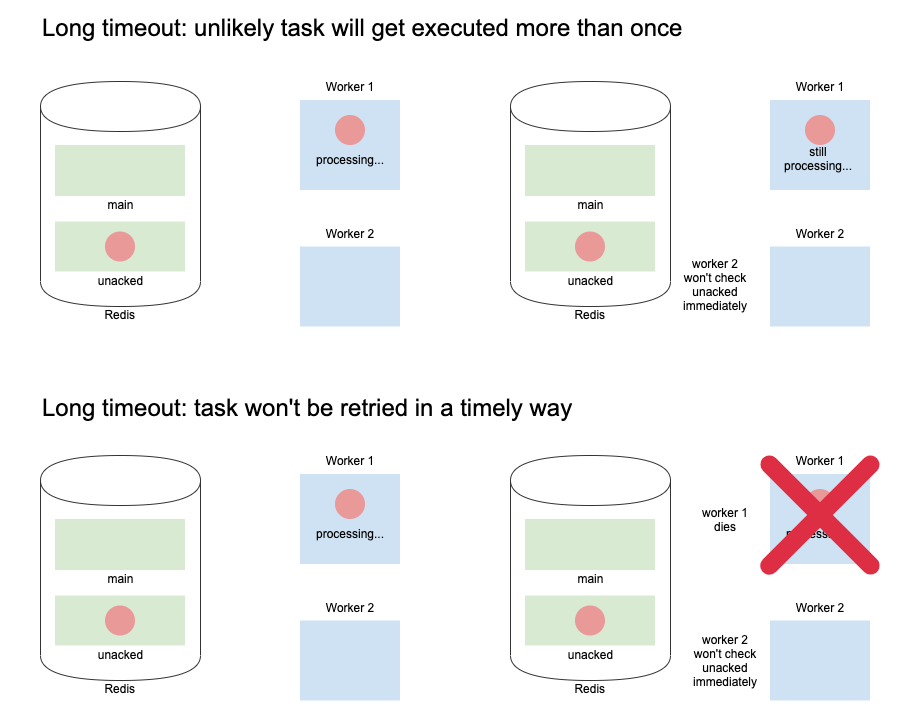
Long Visibility Timeout (24 hours)
Ok, well, it’s dangerous to have too short a visibility timeout, we better just increase it so we never run the same task multiple times by mistake! This time we set the timeout to 24 hours. In this case, a task may make it to a queue, and be held up by other tasks running for 5 minutes and because of the long timeout, it won’t be re-queued, but will run once, ack and be removed from the unacked queue. Problem solved.
What if the task was pulled by a worker, put into unacked and then the worker died for unknown reasons? This means that the task will sit in unacked for 24 hours before another worker finds it and pulls it from the queue to be processed. We’ve just delayed our task for 24 hours inadvertently. In short, there’s no perfect answer. Either we risk running a task multiple times or we risk running it way later than we expect.
Acks Late
One more thing to note is when exactly a task is considered acknowledged/complete. There is a setting that controls how this works. In our environment, we have this disabled, meaning that we consider a task acknowledged when it starts executing. The other option would be acknowledging only after the task is complete. The tradeoff here is between whether it’s more important that a task only execute once or if it completes successfully. If we were to use late acknowledgement, we would potentially re-run tasks that never finished, but had already started doing some processing. We don’t keep this in mind and our tasks are not atomic/homomorphic/have side effects, so this doesn’t work well for our needs.
Countdown/ETA tasks
Now that we have an understanding of the visibility timeout and the unacked queue, let’s talk about using the countdown and ETA features of Celery. They operate in the same way as each other, so we can safely just consider countdown tasks for the rest of the discussion.
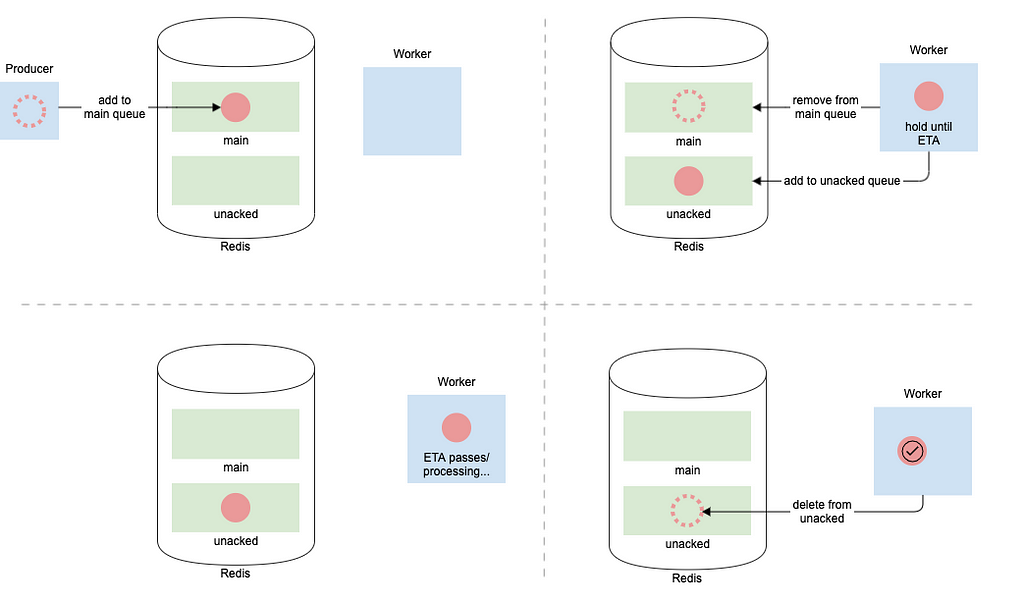
Let’s say we want to delay a task for one hour, the natural way to do that with Celery is to run task.apply_async(countdown=60*60). What happens with Celery and how is this queued?
Two things happen, firstly this task gets passed to the regular Redis queue as usual. It then quickly gets picked up by a worker to cache/eventually execute and placed on the unacked queue. What are the ramifications of this? Well, that depends in part on the visibility timeout. If it’s short, say 30 seconds, it means that other workers will poll unacked and pick up this task every 30 seconds. Since it’s not meant to execute for an hour, it will be queued many many times on workers and execute repeatedly.
Ok, so let’s just increase the visibility timeout to exceed the length of the countdown. Let’s say we make the visibility timeout 24 hours again. Great, now the task will execute well before we re-scan unacked and it will only run once. Though again, we run into the issue of the task potentially executing much later if the initial worker that picks up the task dies/gets killed. It will have to wait 24 hours before being queued on a different worker.
Let’s consider that there are no restrictions on countdown. What’s to stop someone from making a countdown thats 96 hours or 20 days or any other such value? The developer needs to keep in mind both the visibility timeout and when they want to execute a task. Additionally, since these tasks are pushed immediately to a worker, it takes up memory on that worker even though they won’t be executed for a very long time.
Celery at Instawork
At Instawork, we deploy our application multiple times a day. Each deploy means we need to shut down the old Celery workers and bring up new ones. We also use auto-scaling on a few queues that can quickly spin up and spin down Celery workers as necessary. So it’s pretty common for workers to be killed while they’re holding onto tasks.
But, we also have periods of time when there are few to no deploys happening (weekends, holidays, and code-freezes). So Celery workers can live for quite a while and hang on to tasks much longer than we would normally expect.
All of that to say, countdowns are risky business. If the countdown is more than a few seconds/minutes, avoid it. Even in the short term case, try to avoid it.
What to do instead?
We support @periodic_task which is a custom annotation that allows us to run a task on a set schedule. That schedule is configured in settings.py. This periodic task can be leveraged to check database state to then determine if a “real” task should be run. An example of how this can work with something like "fire a notification 10 minutes after a pro's shift ends" can look like this:
@periodic_task
def task_notify_pro(now: datetime, last_time_to_start: datetime):
shifts_about_to_end = Shift.objects.ends_in_range(
last_successful_run_at, now, timedelta(minutes=10)
)
for shift in shifts_about_to_end:
task_notify_shift_about_to_end.delay(shift.id)
Conclusion
If you run Celery in production, it’s important to understand its internals, and to tune settings to work for the types of background tasks your application needs. In particular, you should set visibility_timeout to the right threshold to balance how quickly tasks get retried vs the risk of executing a task more than once. Additionally, eta and countdown need to be used carefully to work with the visibility timeout.
Based on our experience so far, we recommend:
- Do not use countdown or etaon tasks.
- Use periodic tasks with database state to execute other tasks at specific points of time.
- Break down long-running task into multiple, short-running tasks.
There’s still a lot to understand about the details of Celery to ensure that we have a robust infrastructure where tasks run once and only once exactly when we want them to. Do you have any Celery best practices we should know about? Share them in the comments!
Celery ETA Tasks Demystified was originally published in Instawork Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.